Despite it's age, especially in other fields, Kanban is a relatively new addition to the IT world. As someone who is easily just as inquisitive about the development process and working more effectively and systemically, when Kanban was mentioned all those years ago, I looked at the history of the process, put my mathematical hat on, my searching boots on and started to try to understand these systems in more detail.
For those who are not familiar with Kanban, it originated in the manufacturing world. Specifically, it stemmed from the study of supermarket demand in the
1940s which and later became the Toyota production system (TPS) in
Taiichi Ohno's seminal work from 1988. Get that? Started in the 1940's! Some 60 years before IT ever got its hands on the idea.
The method became arguably the most solid foundation in Just-In-Time manufacturing bringing unparalleled and unmatched production quality and speed to the Japanese car market. As a child of the 80s, I remember the sheer envy of the rest of the world of the Japanese market, which at the time outshone the German market for efficiency. It even caused a plethora of Hollywood films about firms being subsumed (aiming to, or avoid) by Japanese companies, such was the dominance of the Japanese car market at that point.
Additionally, whatever you think of process improvement methods, Lean-Six Sigma and Kaizen both use Kanban process as cornerstones of process improvement techniques & there are a number of mathematical and statistical studies of the technique which have also delivered some heuristics to follow. So again, old hat.
As a software development professional, I use Kanban all the time and as an agile early adopter, I have done for a good, long while. However, one thing that always crops up, which I believe is fundamentally wrong, is the notion of tickets moving across the board as the work items themselves. I often have to reiterate the ticket isn't the work item, it's a representation of the needs of the work item. A Kanban signal!
Now, in true [just after] 80s style, you can watch some videos explaining the manufacturing equivalent of the pull system:
https://www.youtube.com/watch?v=w3Ud7pEhpQM
Kanban has been used in manufacturing, healthcare, baking etc. and the only one that I admit to taking umbrage at is the software dev Kanban and here's who. Pay particular attention to how this works! A key takeaway is that information flow, the ticket which includes the 'specification' of the batch size/container, flows from
right-to-left, whilst the implementation (real thing) flows from
left-to-right.
Self-flagellation?
No, I believe in being realistically critical enough about our own work to find the points for improvement. Admittedly, some folk see this as me being negative and make no mistake, there are times I am especially when trying to get some teams to think about change is like head-butting a wall over and over or swimming through treacle - There are only so many times you can keep head-butting that wall before you cease to add value. So companies without the necessary buy-in can learn the hard way when their competitors overtake them and if some staff then leave or are made redundant, they company and staff find themselves without the requisite skill-set to compete with other candidates on the market. It is a huge problem in the IT world especially and one of the reasons why some people were forced out of the industry as agile methods took over.
We also need to reframe this as learning, not criticism. Especially when considering (For those of us lucky enough to have some understanding of optimisation), a theoretically optimal system isn't guaranteed to be unique in any situation! So you can get more than one optimum so there is more than one right answer at the time. In the case of manufacturing or economic systems, this is because there are often more variables than there are equations to solve them (implicit or explicit). So this naturally becomes an optimisation problem with almost always more than one solution, but those solutions do exist and can be found through iterative methods.
Whilst I was involved in the creation of the mathematical algorithm and ran that derivative of IPFP for the UN Development Programme's JOrdanian Social Accounting Matrix in 2012 (based on matrix-raking - it's an iterative algorithm) Kanban modelling doesn't need that level of sophistication. For a lot of problems Linear programming is a sufficient way to look at these systems. However, this is outside the scope of this article, as much as it pains me to say it :) So I'll stick with giving you top-3 tips, but assume you're already segmenting customer feature end-to-end (i.e. entire thin Lines of Business).
TOP-3 TIPS
1. Kanban is a Pull-System
CORRECT! It very definitely is a pull system! So why are you pushing cards across a board? Stop doing it! Think about how you can signal that a task is ready to be pulled. Some folk use smaller green stickers/tiny post-it notes etc.
In my mind, and this isn't shared by everyone (but everyone has been wrong before ;), the ticket represents a container for the item you're producing (whether that is a feature of a system, with many features going into an epic container for the MMF or MVP) or a physical item, such as a container for a 'Login page'. The item is not the login page itself.
The filled container is what the customer wants. If you're Kanban process looks like the following deliberately not perfect example:
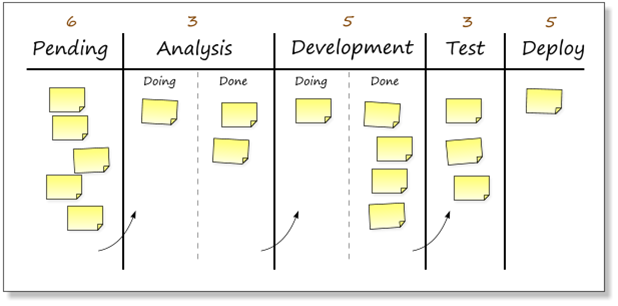 |
| image from bob's lean learning |
The arrows represent where the items go when they are pulled form the previous stage, not pushed once done. At the end of the flow, the deployed container is what the customer gets. The customer pulls this from the test stage once it's ready, which pulls this from the development stage once it's ready, which pulls this from the analysis stage once it's ready, which pulls the 'material' from the pending backlog once it's ready. The specifying pull-signal moves from right-to-left. From customer needs, which effectively specify the acceptance criteria for the system through behavioural tests (BDD/Gherkin) or even just BOLT ("As a... I want... so that...") through to picking up the raw materials (tools, projects, repos etc) at the very beginning. You'll note one crucial and perhaps controversial thing... DEVELOPMENT IS NEXT TO LAST!!!!
Before you start shouting off, this doesn't mean that developers are last, inferior or can be demeaned. After all, you're working in multi-function teams and this is a stage not your job or role right?
Even if you are in charge of it and are feeling insulted or devalued now, ask yourself why that is? Are you protective over your role in the team? Is it Test-Driven Development you are practising? If so, what do you think that truly means? Does the customer care (or is their value measured) by the teasing out or refactoring of tasks which don't pass acceptance tests, glean feedback or deliver much needed value? No, of course not (you better agree!) because the old agile statement about the code being the final arbiter is complete rubbish and has been one that I've thought ridiculous from the start! Whether it delivers value is the true arbiter of the worth of the code and the efficacy of the team. All those feelings of anxiety that may manifest are indicators of 'threat' and dare I say, were felt by the people who were told to move to agile environments some 15 years ago at the turn of the millennium. Indeed, I myself felt them at the time and there is an important lesson in that.
Take a look at this video for 5S a lean manufacturing improvement vendor and see if you can spot some of the things which also conceptually apply to software development (SPOILER ALERT! "All of them") then think about how this can applied in your org:
Or how about this video of a an office space? I think there were more points in this for improvement (HINT: the business cards)
WATCH FOR: No visual indicators of 'ready', usually accompanied by people moving cards into the in-tray of the next stage to the right once complete. This is the same as using 'in-trays' and runs counter to Kanban. QA not being involved (or taken seriously at retrospectives).
TIP: Get small stickers or post-its to show that a task is ready to be pulled, or perhaps have a sub-column for tasks that area ready.
2. Pull-Signals Flow Right-To-Left
Information in the form of pull-signals makes its way from the right hand side of the board to the left hand side of the board. Compare this with a manufacturing plant, where different stages in the process often have differing levels of local inventory, for different parts of the whole. For example 4 screws are used to mount a single kickplate on a door which is pulled as a trolley of doors and kickplates, with the screws at the bench.
In software development a feature is a particular item of meaningful functionality. After going 'backwards' through the testing stage (which remember, is just the container/pull-signal for the work) this may get broken down into smaller architectural chunks, which may have TDD tasks wrapped around them.
Can you see what I am suggesting here? Yes, QAs are effectively your architects. If you're a developer, then I expect there's PANIC! But again, it is TDD you're practising right?...
The truth of the matter is the market isn't currently aligned to this idea at all. Companies still value testers much less than they do development staff and as a result, most people with development skills do not move into testing roles else they earn around 17% less in salary terms, though the contract market is much better aligned. Until this changes, the motivation for better, more technical test staff will simply not be there.
WATCH FOR: Classic indicators of this are where developers run (and talk most at) the stand-ups, a developers is, say, a Scrum master or team lead, the developers drive change, look at technology choices before customer value, the retrospectives are not data driven or are otherwise poor and the team use only one type of testing process (such as TDD) with no attention to behaviour, increment size, load and/or performance testing. Whilst not exclusively the preserve of developers, it indicates both siloed thinking in job role and no strength being attributed to the test side of the team.
TIP: Encourage buy in from the team and make them aware that the QAs run the testing process. Encourage pairing for KTP and the breaking down of features led by the testers, not the development staff.
3. Business Analysts are also your Feedback!
More often than not, a business analyst is found on a team and they illicit requirements. They also look at the business process at hand and determine the value of the tasks but rarely do I see a business analyst be involved in decisions and reporting ROI and team and capability effectiveness. This is the missing link.
When working lean, the aim is to get feedback on how well the business vertical is working. A business analyst does exactly that! They have to look at the customer value of each and every story and determine the cost-benefit of doing each [thin business vertical] task. They will also help determine the Rate-Of-Return and the Return-On-Investment of a project in the customer's mind as well as look at the customer experience elements, both inside the outside the team. Together with the QA's they are crucial in determining how effective the team are, how well they are working together and determining the scope, location and exposure to any points of waste or constraints in the process. They will be skilled at determining the appropriate contextual metrics and constraints (a bank is different to a mobile social media app start-up) and monitoring the necessary measures of value.
WATCH FOR: Retrospectives without numbers or no change in waste, blockers or bug numbers in each iteration over a period of time or no predictability in flow. This is likely nearly every one you'll ever attend (and is why they're wrong). Some companies, such as Lastminute.com have moved up a level, but they are very very rare!
TIP: Get the business analyst to think about operational expenditure and how the team adds value. If you take the brave (but I think legitimate) step of align reward to profitability, then the business analyst will be crucial in determining that for the team. This will include finding the internal independent variables influencing flow, cycle-time and throughput/velocity, such as number of blockers, bugs, enhancements and other levels of waste.
Summary
Moving to lean from just plain agile is a tough ask for a lot of companies anyway, whichever field they're in. This article gives you necessary but not sufficient things to look for when walking the floor at your company.
Note, there are better companies out there than us in other fields and we are guilty in the IT world of not being humble enough to understand that. It isn't that the problem of Kanban is any different in software or product development (at least I can't see a significant difference), just that our grasp about what a batch or container is, is very muddy. We can and do use story points, but need to attach these to features which combine into epics and hence make up MVPs and MMFs. Other techniques such as creating thin slices of functionality reduce the variance enough to introduce a reasonable element of predictability into the container or batch size.
We also think that development is the cornerstone of the business, which any CEO will tell you, isn't true. It's an enabler, often to a product or service which pre-dates computers. If they could get something to do it as fast, but without the development overhead, they'd choose it over developing software any day, as there is much greater uncertainty in software. We already see this inside the IT space with build or buy decisions. So the role of business analyst and QA is crucial in process optimisation and it certainly isn't the preserve of the development team.
Teams inside and outside organisations need to make sure they understand that they are also part of the
value chain. Your customer takes a problem, adds value in the solution they create (which includes the software they get you to write) and 'sells it on', providing a solution to their own customers, who may be Joe Public. If you've worked in B2C or B2B service companies before, this is always the case. Being in IT doesn't lose you the economic reasoning and truth be told, in capitalist environments, I think that's unforgivable if you think that's the case.
Happy Leaning!
















